
Data integration is the process of taking data from multiple sources and combining it to achieve a single, unified view.
The product of the consolidated data provides users with consistent access to their data on a self-service basis. It gives a complete picture of key performance indicators (KPIs), customer journeys, market opportunities, etc.

Data integration is important for modern business because it has the ability to:
Doesn’t that sound great?
But before we go any further, let’s cover some basics that you’ll need to understand to get started.
The definition of data, in its broadest sense, is information recorded and then formatted in a certain way to be stored for future use. Data can be quantitative, such as numbers, quantities, measurements, etc., or qualitative, such as facts, observations, interviews, etc. It can also be structured, for example, Excel files or SQL databases, and unstructured, for example, audio, video files or No-SQL databases.
It’s fascinating to think that the first evidence of humans recording data dates back to 18,000 BCE with tally sticks. Discovered in 1960, The Ishango Bone is considered to be one of the earliest pieces of evidence proving prehistoric data storage. It’s fair to say, we’ve come a long way since our prehistoric ancestors were etching notches into sticks or bones to keep track of supplies and trading.
Flash forward to the 1600s and we see the emergence of statistics from Statistician, John Graunt, who recorded mortality rates that occurred during the Great Plague of London - an outbreak of the bubonic plague.
A little later in that century, in 1665, the term business intelligence was first used in reference to banker Henry Furness’ structured and analytical process of recording his business activities.
Then, in 1880 a young engineer named Herman Hollerith saved the US Census Bureau almost 10 years of work by creating the Hollerith Tabulating Machine, making himself the father of automated computing.
As time went on, data became more complex and voluminous, and the speed at which it was created went beyond human comprehension. In the 1990s, around the same time that the internet became public, we started referring to this mass of information as ‘Big Data.’

Big data is a term that refers to large volumes of data, both structured and unstructured; it particularly refers to new forms of data that is produced at an overwhelmingly fast rate.
Related reading: The Pros and Cons of Big Data
Big data sets are too large and complex to be processed by traditional methods. Consider that in a single minute there are:

Source: SAS
The easiest way to conceptualise big data is to think about the 3Vs:
Some argue that today, you also need to think about a fourth V: Veracity; this is the accuracy of your data. Having inaccurate data is worse than having no data at all.
[Infographic] Big Data Ethics
The data that we refer to as ‘big data’ is so large, fast-growing and complex that it is almost impossible to process it with traditional methods. Luckily, new methods such as machine learning and data integration have been developed which leverage new technologies allowing the automatic processing of vast amounts of data and extraction of valuable insights for modern business.
There have been 3 main phases in the evolution of big data:

Source: Big Data Framework
Companies who wish to remain competitive in the markets of today and in the near future must embrace big data to survive. Data integration is essential to the future success of a business as it provides unparalleled business intelligence, data analytics, enriched data, and real-time insights.

In data integration, we talk about combining data from multiple sources, and you might be wondering what data we mean. Well, modern companies - even those that are smaller in size - have adopted numerous digital tools to assist them in their day-to-day operations. These can range from marketing and sales tools to logistics and transactional processing tools.
For example, a small enterprise with ten staff members may not think they need data integration but let’s add up their tech stack:
We can see from this analysis that even a small team with basic operational needs uses multiple tools; all of these tools create data that without integration processes will result in detrimental data silos.
Data integration is a complex process and there’s no one universal approach that fits every situation or organisation, especially as many of the IT technologies used to carry out integration are constantly evolving.
Data integration methods can be broadly categorised into 3 types:
1. Manual
Manual data integration is labour intensive, involving hours of copy-pasting, CSV uploads, spreadsheets, frustration, time-wasted, etc.
2. Automated
Integration libraries full of APIs are used to automatically sync with ‘one-click’.
3. Engineered
Custom APIs and webhooks are created and maintained by an engineering team to create data-flows and enable integration.

Source: Software Advice
There are several key steps to any technique of data integration, the first is data ingestion; this is the process of collecting the data from all of the sources to be moved for further analysis. Since the data comes from multiple sources, it needs to be cleansed so that it is uniform and can be interpreted.
The process of data ingestion can be complex, and traditionally, many organisations opted to use ETL solutions that handled the brunt of the heavy lifting for them.
ETL stands for:
Extract - the tool extracts the necessary data from the source by using connectors or the source API.
Transform - due to data coming from multiple points of origin, it is then standardised (formatting values such as currencies, time-zones, units of measurement), enriched and validated (missing values filled and duplicates discounted) to ensure consistency at the end-point.
Load - the newly transformed data is loaded into the central location to be used for analysis and reporting purposes.

Source: Software Advice
In the past, ETL solutions have been effective in handling small or medium-sized, structured data-sets for organisations that have on-premise databases. However, as the data that companies produce rapidly multiplied, and the need for unstructured data to be included for accurate analysis increased, data ingestion tactics began to shift toward a more modern approach known as ELT.

Source: Software Advice
ELT extracts and loads the data into the target location and then transforms it after it is loaded. This approach takes advantage of cloud computing to harness speed and scalability and integrate data in real-time.
![Explain The 3V's of Big Data [View Infographic]](https://no-cache.hubspot.com/cta/default/2080894/2b602f94-515b-49c6-810f-32c819f71e20.png)

Source: Advice
The ELT process is better suited to the needs of companies that operate with unstructured data and larger data lakes. Considering that 80% of enterprise data is unstructured, it makes sense that ELT is increasing in popularity.
Related reading: Data Warehouse vs Data Lake: What's The Difference?
Later in this guide, we will discuss other methods of data integration. Click here to skip ahead.

Source: CMS Wire
Business that had implemented legacy systems modernisation can increase annual revenue by 14%
Source: SPD Group
People are resistant to change; within many enterprises, it takes a lot of convincing before action is taken to onboard a new process or software products.
Oftentimes, whether it is down to tight-budgets, staff-abilities or reluctant management, legacy software systems are kept in-place far past their prime. And, with accelerating technologies, even when companies do decide to update their legacy systems, the new systems can become out-of-date after a few years, and this cycle repeats, causing companies to become even more resistant to change.
Companies need to become committed to innovation in order to compete in the data age.
Poor data quality costs the US economy up to $3.1 trillion yearly
Source: Techjury
Quality data is the key to achieving profitable insights with data integration. However, 77% of businesses say they have data quality issues.
Having poor quality data is a waste of everyone’s time. To avoid poor quality data impacting your integration results, you need to develop data management processes that start by evaluating the current state of your data, commit to data cleaning, minimising, and standardisation.
What makes your data poor quality? The 3Is:
Related reading: What is Data Integrity?
The global cost of cybercrime fallout is expected to reach $6 trillion by 2021
Source: Herjavec Group
Companies are responsible for the data they hold, they need to protect it heavily to avoid it falling into the hands of cybercriminals. However, data is also vital to business operations and many users will need to access, modify, copy, or move this data from IT systems on demand.
Problems with data access can occur when the correct precautions are not taken to create data access and vetting processes. Additionally, when time is not invested in training staff on the importance of data security, costly errors can occur such as data leaks or GDPR breaches.
In recent years, there has been increased employment of data analytics experts who undertake complex projects handling larger and larger data sets. As a result, IT departments are failing to keep up with data access requests in real-time. Improper data access means that lapsed or blocked access permissions can deny or complicate access for users who need it for business intelligence.
![What is Data Integration? Simplified [Read Blog]](https://no-cache.hubspot.com/cta/default/2080894/eded44e0-bf46-4483-ac15-ef2b40a1c950.png)
In order to perform successfully for a business, marketers need to base their actions and decisions on structured information.
You can be the most qualified, experienced, knowledgeable or creative marketer out there, yet, you will still need strong data to guide you. Why? Well, every business is different, every customer is different, so to be able to best promote your company, product or service to your target audience, you need data-lead, analytical insight. For your marketing campaigns and strategies to truly be successful, you need data that’s specific, free of errors and, importantly, unified.
Related Reading: A Marketer's Guide to Data Warehousing and Business Intelligence
Data is evolving faster than ever, as are the ways in which it is processed. And, as a marketing professional, you need to utilise every piece of information that you can grasp.
When you think about it, marketers today are active on so many platforms in comparison to even the past 10 years. Everything from social media platforms like Twitter and LinkedIn to email marketing solutions, CRM platforms and Google Ads & Analytics - all of which continually gather huge amounts of usable data.
But how can you efficiently utilise all of the information available to you in a succinct and actionable way when the data resides in disparate sources and has contrasting formats?
This is where marketers can benefit from data integration.
Data integration provides a single, unified view as it merges data from multiple heterogeneous sources. In basic terms, typical data integration will involve a network of sources, a master server that pulls data from these sources and businesses accessing the data from a master server that holds the unified data which is now in a structured, usable format.
The keyword here is usable.
One of the most common applications of data integration is a ‘data warehouse’; a centralised location for the storage of company data. We will go into further detail about data warehousing later on.

First, let’s take a look at the 3 primary reasons why marketers need data integration:
Marketers deal with a wealth of data on a daily basis; customer data, campaign analytics, budget information, and so on. To add to this, marketers often need access to data from different departments in order to tailor strategies. Customers, and therefore their data, often move between sales and marketing departments depending on their stage in the buyer’s journey; if the individual is in the ‘awareness’ stage - they will need the marketer’s creative and insightful content to give them a healthy idea of what it is the company does and why you’re the right choice for them. Then, if they carry on their journey and, say, are ready to make a purchase, they will have moved into the ‘decision’ stage where they will be communicating with the sales team.
The unified view that data integration facilitates makes inter-system cooperation possible, meaning your company is free from data silos that obstruct departmental teamwork.

Source: Forrester & Google
Integrating data from multiple sources gives marketers and sales teams a more complete and structured understanding of customers; their behaviours, touchpoints and pain points. These accurate, actionable insights are key for providing seamless customer experiences, tailored communication and optimised output.
Inter-system cooperation optimises a company’s overall business intelligence, too, as the insight gained from data integration allows for a deeper understanding of information that’s needed for streamlining business strategies and operations.
Not only does data integration provide a unified view of scattered data, but it also maintains the accuracy of your information.
When data is gathered manually, every tool, database and customer account must be accounted for. This means that any data source that’s overlooked, added at a later date or accidentally included more than once results in a data set that’s inaccurate or incomplete which can affect the business as a whole. Manual data handling also means that reporting must be re-worked whenever new data comes in.
Data integration prevents the risk of human error by updating source systems in real-time. Without an effective data integration solution in place, reporting must be periodically repeated to account for any changes or new information. With automated updates, reports can be run, accessed and utilised effectively and in real-time.
When a company successfully integrates data, the time it takes to identify and analyse this data is significantly reduced when compared with data that’s held in silos. Imagine you have a business question that needs to be answered; the data is spread across multiple sources therefore you have to delve into different systems to gather all of the required information to find your answer. This is do-able, of course, but if your question is time-sensitive then manually gathering and analysing this data can mean that once collected, the information and outcome is no longer relevant or accurate.
Data integration makes collecting, converting and analysing your information smooth and painless, saving you time and boosting efficiency.
Not only does this benefit you because you get your answers and outcomes in a more timely manner, but having properly-integrated data from multiple source systems gives you more time to focus on other marketing tasks.
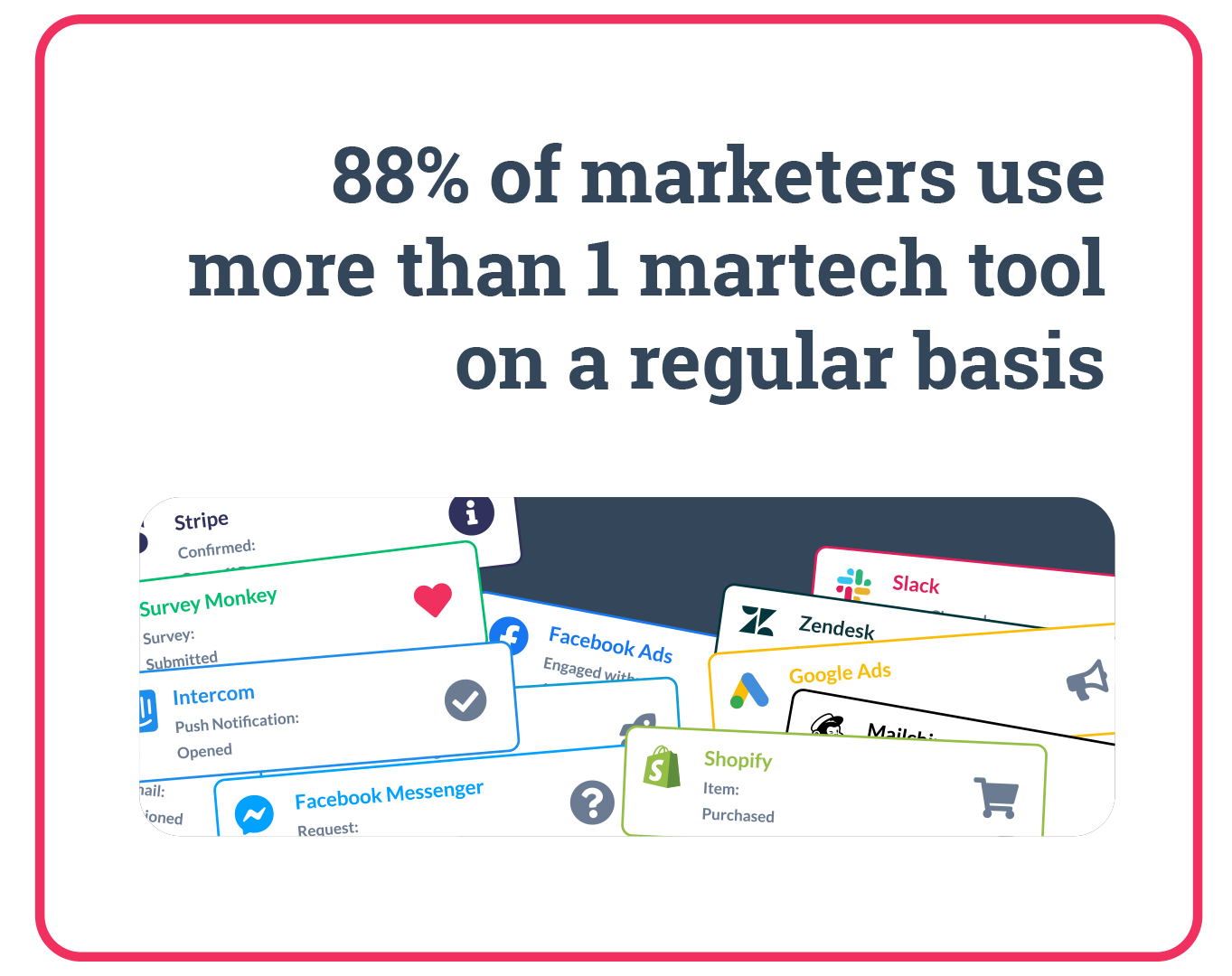
Source: Walker Sands
Most marketers (over 50%) say that they struggle with 4-10 poorly-integrated tools when trying to reach their audience.
Unorganised data can leave marketers feeling overwhelmed and deflated. Integrating your data helps to gain insights into the customer journey, streamline marketing efforts and optimise campaigns, reporting, and, overall, make your marketing as customer-focused as possible.

Companies are forever seeking to keep up with industry leaders and competitors. If they haven’t already, they must embark on an omnichannel approach to marketing.
Omnichannel is, in a way, an industry buzzword, but it’s not without real, genuine significance. If we break down the words, we have Omni meaning all and channel which refers to the different platforms and mediums where customers can connect with brands (and vice versa).
When you put the words together in the context of business or commerce, omnichannel describes the experience a customer has with your brand across your various platforms and outlets. Take your sales and marketing communications, your social media profile, your brick-and-mortar store, your website, or your app’s interface… for you to truly be offering an omnichannel experience, your customers’ interactions with your brand must be seamless no matter what device is being used or whether they're online or offline.
To make a sweeping generalisation, the key goals of most companies will look something like this:
And so on.
Across these goals, there’s a common requirement; access to, and proper utilisation of, customer data. It is impossible for brands to achieve goals such as these when their customer’s data is fragmented and siloed across disparate channels and martech tools.

Source: Omnisend
In order to overcome the issues that fragmented and siloed data presents, such as wasting storage space and offering an incomplete view of the business, companies must be able to unite their data. Once a business’s ecosystem is connected it is then possible to utilise consumer data and facilitate the omnichannel experiences that consumers now expect.
The customer journey isn’t simple or linear; it’s composed of a series of actions made via different mediums, both traditional and digital. Take retail stores, for example. They typically have multiple channels that customers engage with. They might have an app where customers order their shopping and request home delivery; these customers may also log into an account via a store’s website, add a few essentials to their shopping list and select to collect these items in-store. Additionally, shoppers could have a physical loyalty card that is used to collect points and access discounts in-store.
In order for these consumers to remain loyal, they require integrated transactions, and the ability to move freely between channels without the worry of losing control or finding inconsistencies in the product, service or information they receive. They also expect brands to be reliable, speedy, flexible, caring and consistent.

Source: Omnisend
The evolution of information technology and devices means that a lot of consumers already practice an omnichannel approach; making actions on a brand’s mobile app and switching to their website, and then following up digital actions in a brick-and-mortar store, and so on. This means that brands are now required to keep up which, for some, poses a challenge. But those companies who do opt for the data-first approach are able to gain an improved understanding of their customers and the wider market which enables a significant competitive advantage.
Customers offer a lot of information about themselves; their name, email, telephone number and so on. When they provide this information, they don’t want to be asked for it more than once. As well as keeping a record of their personal data, customers now expect businesses to keep an account of their purchase history and actions made across different channels. When companies implement data integration, information from their existing channels and systems is shared and updated for improved operational efficiency.

Source: Omnisend
It’s important to remember that data is complex; the volume, variety and velocity of data currently available are monumental and growing continually. The key to success, here, is to leverage all of the data available; customer touchpoints, pain points, sales data, etc., and integrate it to create a sophisticated view of the customer journey.
Data-centricity leads to customer-centricity; without data integration, a 360-degree view of the buyer’s journey is not possible and, as a result, neither is a seamless omnichannel experience.
![What is Data Integration in Marketing? [Read Blog]](https://no-cache.hubspot.com/cta/default/2080894/ba6c230b-67e6-4afa-bd1d-07f1c275c28d.png)
![Big Data for Beginners: Improve Your Marketing Strategy [Read Blog]](https://no-cache.hubspot.com/cta/default/2080894/3e74e831-9f19-406f-992a-27d5a31d73b2.png)
The enormous value that big data can bring to organisations is evident, however, managing huge amounts of diverse datasets comes with many different challenges. According to a report from Salesforce, marketers keep track of customer information on an average of 15 data sources, which has increased from 10 over the past two years. This is where the need arises to have a data integration solution in place to collect, combine and analyse all the data coming in from the various sources, displaying it in the one place, and making it much more digestible and insightful to the company.
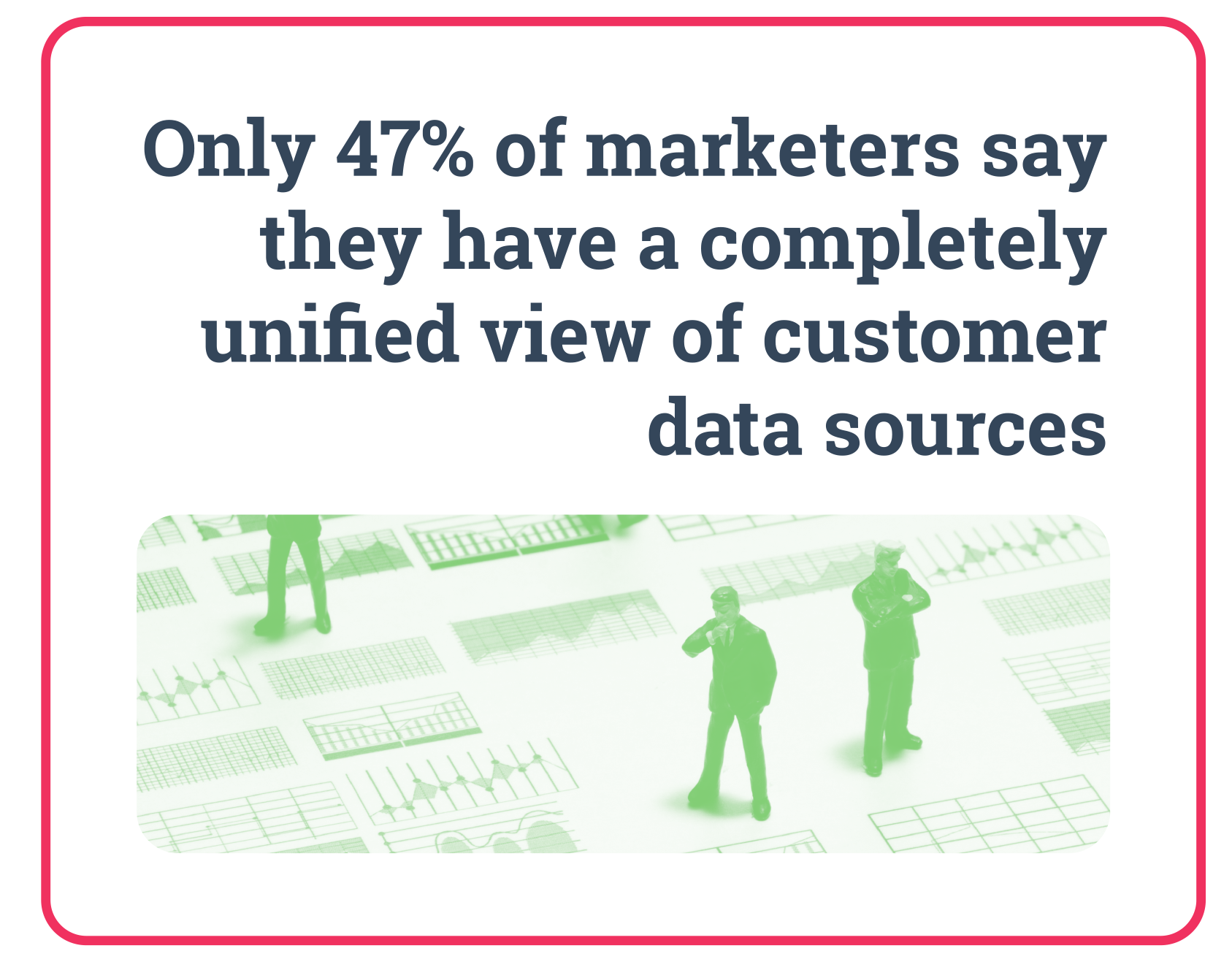
Source: Salesforce
With the right big data integration solution in place, business owners and marketers should have the ability to:

Without data integration, customer information simply exists in servers that are accessible by one department but isolated from the rest of the organisation, sometimes also in different formats and providing little-to-no business value.
Isolated data of this kind is known as a data silo and results in poor communication between departments, systems and processes. Data silos ultimately lead to an inability to meet both customer needs and business goals. Plus, when data is siloed important decisions are made based on incomplete and inaccurate information, which can cause customers to lose any trust and respect for a business.
It’s important to be aware of the detrimental impacts of data silos to your organisation, so let’s take a look at some of these issues in more detail:
1. Data silos reduce productivity
When your data exists in multiple places, you have to spend a lot of time searching through tools, files and spreadsheets. In fact, more of your time is probably spent looking for the data, rather than actually analysing and deriving something useful from it. Think of how much more productive you could be if the data had already been streamlined into one source.
2. Data silos waste resources
A knock-on effect of having inefficient processes is the waste of resources including time, money and so on. When your employees are having to dedicate so much unnecessary time to delve through lengthy, unorganised records of data, this ultimately takes away from the time spent reaching milestones and goals that are aimed at driving profitability.
3. Data silos waste storage space
Duplicate copies of the same data saved to the company storage folder can put a huge strain on a business’s budget for storage space. Streamlining data into one source that is accessible by the entire company will help free up space and ease the pressure on the IT department.
4. Data silos threaten brand integrity and revenue
Data that exists in multiple databases, used by multiple departments, will eventually become inconsistent and inaccurate. Over time, it becomes more difficult to keep all records in sync and up to date should they exist in different systems. Data is constantly changing. This means you might end up with the incorrect email, name, address or job role of a customer or prospect, resulting in your sales and marketing team reaching out with the wrong messaging, or failing to be able to get in contact at all. These sorts of slip-ups are inexcusable with the technology of today and will damage your brand integrity, and lose you business.

Source: The State of Digital Customer Experience - 2019
5. Data silos discourage teamwork
Collaboration and teamwork is a vital aspect of many data-driven organisations, especially with the rise in remote work as a result of the COVID-19 pandemic. However, when data is siloed, making it difficult or impossible to share, collaboration is likely to suffer as a result. This lack of transparency can have a negative impact on business goals, as well as your overall employee morale and communication.
Luckily, all the issues discussed above can be solved using the process of data integration. Integrating all the various software and tools where your data currently resides into one platform with a single, unified view will help to eradicate the problem of data silos.
It’s not uncommon for business owners and managers to think that importing and exporting data regularly is enough to keep your records up to date. However, this is a huge manual undertaking and, as we’ve previously discussed, a great waste of employee time and business resources. Plus, you’ll still never fully be confident that your data is accurate due to the possibility of manual data entry errors.

Data copies can be sent both asynchronously (at different times) or synchronously (at the same time). Synchronous data propagation uses two-way communication between the data source and the target datastore. Asynchronous data propagation occurs when changes are made to the source data, and the updates need to be pushed to the target data store. In this case, the source does not wait for the target’s acknowledgement before forwarding updates.
Both EDR (enterprise data replication) and EAI (enterprise application integration) technologies support data propagation for different purposes.
EDR, a method that simply copies data from one storage system to another and does not change it in any way, is used to send large amounts of data between remote and central locations.
Whereas, EAI integrates business applications for the easy sharing of data, messages, and transactions. EAI data propagation is primarily used for business transaction data, for example, e-commerce optimisation, because of its ability to function in real-time.

The term federate means to ‘link-up’ or ‘form into a single centralised unit’, which is a great way to understand data federation.
Data federation refers to a technology that builds a type of ‘bridge’ (known as middleware) to link data from multiple sources and formats together in a single view.
The bridge consists of a relational database management system (RDBMS) - a program that allows analysts to identify, access, and maintain information in relation to other information by forming tables of data consisting of rows and columns. This process of organising data into tables is known as a data model; federation uses a strict data model to form the single-view visualised at the endpoint.
The RDBMS system standardises the disparate data sources into a unified, virtual network that operates using SQL (Structured Query Language) and can be viewed and searched as one database. Analysts can make a single SQL search request that returns results in real-time despite geographical location or formatting differences of the source data.
The data that passes through the bridge is not copied or replicated but virtually represented at the end-point; source systems’ data remains unchanged.

The evolution of data federation produced data virtualisation; the two methods have the same principles at their core, but the later progresses further in terms of power and capabilities.
This type of data integration is used as an umbrella term for data management processes that retrieve and manipulate data from multiple, disparate sources without requiring technical information like data formatting or the physical location of that data.
Virtualisation techniques allow structured data and unstructured data to be accessed in a single interface representation via a visualisation tool. An important distinction of virtualisation, like federation, is that data is not copied or moved from the source, but rather, integrated virtually.
Essentially, data virtualisation software is middleware that enables a simplified, virtual representation to be created in real-time. In its evolved form, the difference between federation and virtualisation is that virtualisation does not apply a data model.
Rather than standardise the data to present a single-truth, the virtualisation abstraction layer separates the ‘logical view’ of data (the information needed for analysis) from the physical representation (metadata and integration logic). The metadata is stored within the abstraction layer and hidden from the end-point.
Metadata provides context to business data allowing analysts to obtain more value from the information; this can include file titles, formats, dates, authors, where data is stored, what application or technology is used to store data, etc.
Virtualisation allows data scientists to access, search and interpret metadata easily, and if necessary, combine it with logical data for reporting. The simplified nature of virtualisation saves data scientists processing time and optimises data for business intelligence.
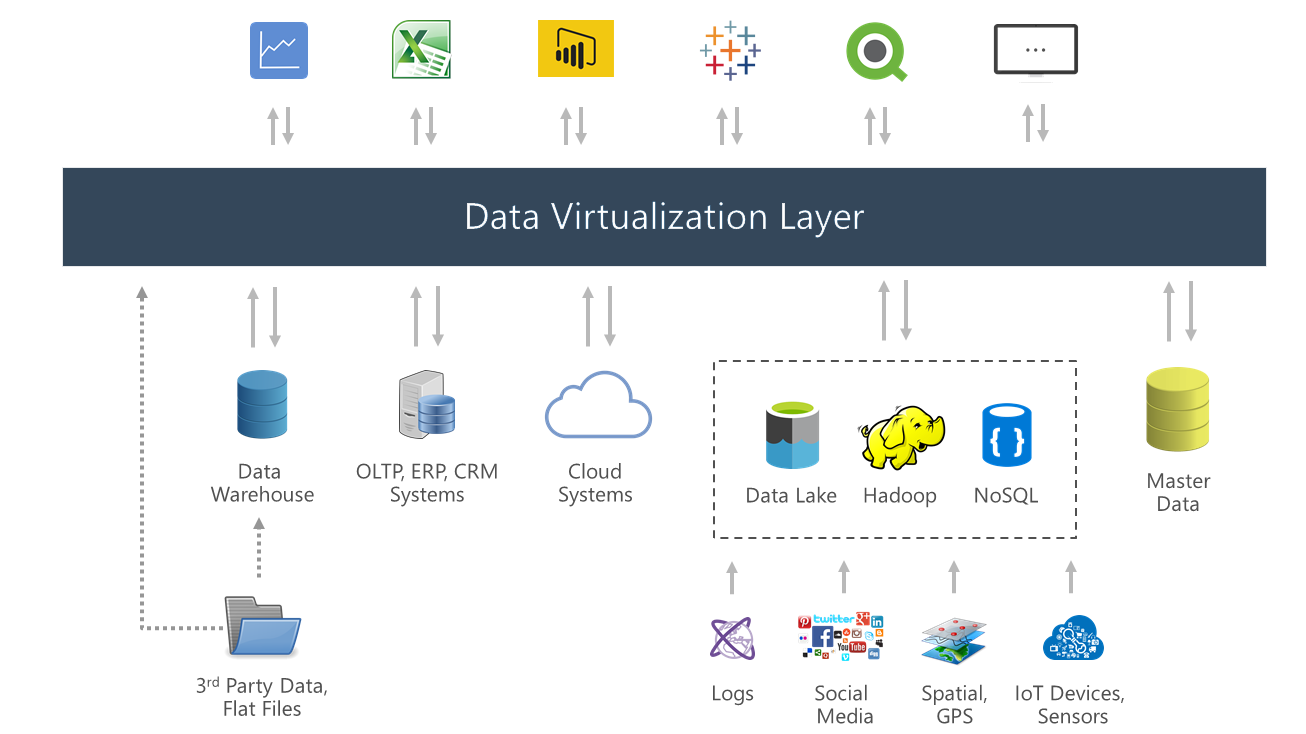
Source: Querona
Here are some key capabilities of data virtualisation to remember:
One of data virtualisation’s popular use-cases is to ensure compliance with the European data privacy laws, GDPR, as it allows businesses to avoid a hefty fine.

Source: Gartner

Application-based integration is the process of facilitating individual applications, each with their own particular purpose, to work in tandem.
With application-based integration, software applications do all of the work. As opposed to manual integration, software applications locate, retrieve, clean and integrate data from disparate sources using an API (application program interface) to communicate. Or, as Astera puts it:
The definition of application integration is the combination and improvement of workflows and data across software applications. The end goal of this process is to enhance business efficiency. However, enterprise application integration particularly focuses on communicating between various systems.
Application-based integration is sometimes referred to as enterprise application integration as it’s commonly used by enterprises working in hybrid cloud environments (hybrid cloud integration connects on-premises and local servers with private or public cloud resources for the purpose of expanding data management storage and processing capabilities).

The compatibility of application-based integration makes it easier for data to move from one source to another. However, this process is only manageable when there’s a very limited number of applications.
A data warehouse is a consolidated repository used for storing data assets collected from different applications. Data warehousing implies cleansing, formatting and storing data primarily for the purpose of research, answering business-related questions and generating analysis. Originally created to help transition data, it has come to be used to fuel decision-making and reveal business intelligence.
The data warehouse approach is one of the most common business uses of data integration which periodically pulls information from apps and systems, where the data then goes through formatting, into a master relational database.
Data warehousing is a popular data integration technique due to its versatility - it allows organisations to run queries across integrated sources, compile advanced reports and analyse collected data in a uniform, usable format across all integrated data sources. It is, however, more costly in both money and employees’ technical ability.
In today’s data-driven world, integration is one of the best ways to gain business-critical insights and achieve a competitive edge, which is why it’s critical for an organisation to choose the right strategy.
To design an effective data integration strategy, it’s essential that you evaluate the scope of your data and look beyond the initial integration projects. As your company evolves, so will your data, and your integration strategy needs to account for this.
The data-to-insights journey is significant to organisations big and small and integration is a critical step in that journey. Each of the techniques we’ve explored has different strengths and weaknesses, and whichever an organisation chooses to use within its business will offer benefits of some kind. Data integration enables companies to unite their data and realise the value of integrated information. No matter which technique you decide to implement, data integration will improve your business’s decision-making and enable you to effectively uncover actionable customer insights.

One of the key benefits of data integration is that it enables analytics tools to produce more effective and actionable business intelligence.
When we talk about business intelligence, we aren’t just referring to one specific ‘thing’. The phrase is more of an umbrella term that covers the various different processes that involve the collecting, storing and analysing of business data.
BI is a collection of software tools, supporting infrastructure, and data practices that are designed to leverage enterprise data to improve business decision-making. With BI, managers and stakeholders can view present and historical company data and easily spot market trends. The process enables organisations to gather the necessary data, analyse it, and then use it to make smarter, data-driven decisions that help the company run more efficiently and be more profitable.
Here are just a few things a great business intelligence process can help you do:

Source: MicroStrategy
Most businesses use a number of different platforms and sources for storing various organisational information. In order to gain the best business intelligence possible, this data will need to be cleaned up and replicated in one system to allow for analysis. This is where data integration comes in by compiling your multiple data sources and delivering them in an easily consumable format in one unified view, making it a key part of the analysis process for BI.
With the ever-increasing volumes of data available to businesses today, BI is a requirement if you wish to unlock the true value of your data and remain competitive in your industry.
The average company with around 200 - 500 employees uses about 123 Software-as-a-Service (SaaS) applications (i.e. CRM, ERP, POS) across many of their different departments to keep the business running smoothly. Having data that exists in many different tools often leads to it quickly becoming fragmented, inaccurate, duplicated and out-of-date.
When this occurs it becomes nearly impossible for managers to accurately gain answers to some of the most basic business questions such as “what products have the best margin(s)?” and “who are our most profitable customers?”
Incomplete or inaccurate data can cause issues directly between your business and your customers. For example, if one of your sales representatives contacts a customer and tries to sell them something they have already purchased, or if your accounts team were to chase up a client for an unpaid bill and they had updated their address, but it wasn’t consistent across each system. Either of these scenarios could be damaging to new and existing customer relationships, causing them to question your reliability and professionalism.
To help deal better with these challenges, many business owners turn to master data management.
According to Gartner;
“MDM is a technology-enabled discipline in which business and IT work together to ensure the uniformity, accuracy, stewardship, semantic consistency and accountability of the enterprise’s official shared master data assets. Master data is the consistent and uniform set of identifiers and extended attributes that describes the core entities of the enterprise including customers, prospects, citizens, suppliers, sites, hierarchies and chart of accounts.”
Essentially, it involves creating one master record for each customer, product, location or thing within a business, by merging information from across both internal and external data sources and applications. This master record is sometimes known as a “golden record” or “best version of the truth” and serves as a trusted version of critical business information that can be managed and shared across the organisation to promote accurate reporting, reduce errors, remove redundancies, and help employees make more informed decisions.
MDM cannot function properly without integration, however, integration is also one of the biggest challenges when it comes to implementing a master data management solution.
Merging lists together to create the master record can be tricky as it’s common for the same customer to have different names, contact numbers and addresses across the different databases. For example, Alexandra Wilson might appear as Alex Wilson, A.Wilson, and so on.
A standard database merge will not be capable of recognising and resolving such differences. A much more powerful tool with a more sophisticated data integration capability will be required to pick up on the various nicknames, alternate spellings and typing errors that may occur. It will also need to understand that variations in name spelling can be resolved by recognising if the contact lives at the same address and/or has the same phone number.
MDM solutions involve a broad range of data cleansing, transformation and integration processes. For each data source that is merged with the system, MDM initiates the required processes to identify, collect, transform and repair data. Once the data meets the quality thresholds, a framework is created that helps maintain the high quality of this master record.
In the age of omnichannel, businesses are engaging their audience using more platforms than ever before. This approach has provided companies with new avenues for business growth, promotion and strengthening customer relationships. However, this has also made it difficult for companies to keep track of all the touchpoints available to their customers. Data is what powers the agile, automated, personalised, omnichannel experience that customers want. For businesses, data enables them to understand who their customers are, how they shop, what they purchase and how they engage with their brand.
When it comes to analysing data results, if certain touchpoints are not accounted for in the overall reporting then the results will be inaccurate, causing any subsequent business decisions made to be skewed. To prevent this from happening businesses can utilise data integration and have an avenue to gather and merge data from a range of sources into one, cohesive resource. With this, business owners and marketers have a complete view of their customers with data from every possible touchpoint unified in one place, for example, website, social media, advertising, mobile, e-commerce, POS, and more.

Source: SuperOffice
With a complete customer view, businesses will be in the best position to improve their customer experience by knowing exactly what their customers want and when.
Whilst big data has brought with it a huge amount of new opportunities for businesses, it can also sometimes become overwhelming. With such large sets of data to go through it can be difficult to see the bigger picture. This is why data visualisation tools and technologies are a vital part of analysing mass amounts of information to enable data-driven decision making.

Data visualisation is a graphical representation of information and data. Through the creation of graphs, charts, plots and other images, data visualisation tools graphically illustrate data sets to see and understand any hidden patterns, trends and relationships within the data. Our eyes are naturally drawn to colours and patterns and, for most, we can much more quickly make sense of something when it’s in a visual format, rather than just staring aimlessly at a massive spreadsheet full of data. By transforming large amounts of numbers and text into clear visuals they suddenly become much more meaningful to the person seeking answers and information to guide their decisions.
![]()
![]()
Source: Tableau
For data visualisation tools to be most efficient, they should have prebuilt connections to load and integrate data from a wide variety of sources. With a data integration capability, businesses are limited only by their imagination in terms of the data that could be merged into a visual format. The opportunities for analysis become endless and it enables organisations to hone in on what matters to them.
With data being one of the most important assets to a company, it’s important to protect its integrity. Data integrity refers to the overall accuracy, consistency and completeness of the data stored in a database or data warehouse. It also involves the safety of the data in regards to data security and regulatory compliance such as GDPR.
There are two types of data integrity; physical and logical:
Before data becomes useful for aiding business decisions, it must first undergo a variety of changes and processes to take it from its raw form to one that is more practical for analysis. Nowadays, data is mostly digital and it is not static, and so it gets regularly transferred to other systems, altered and updated multiple times. This is how data integrity and data integration are very closely related. How good your data integration software is will have a direct impact on your data integrity.
As it is being transferred or replicated between regular updates, and as new varied types of data are being collected, it should remain unaltered. However, sometimes integrity can be compromised. This can happen from:
Without integrity, data is not really of much value. In fact, data that has become corrupted or compromised can actually become incredibly harmful to your business and damage your credibility. Not to mention the danger that could come with the loss of potentially sensitive customer data. Protecting your data integrity can seem overwhelming, however, with the right integration platform you can easily and securely merge your data and have the most up-to-date view of all your information in one location.
Now that you have a fundamental understanding of what data integration is, why it is beneficial and how it is necessary for your business’s future, it’s time to start designing the data integration strategy that’s right for you.
We’ve already discussed the different types and techniques of integration, so you know that you have many choices to make, and that can be overwhelming. But really, data integration should be simple as it all depends on the requirements of an organisation. Your organisation’s ecosystem will tell you precisely what you need when it comes to data integration strategy.
One debate that will need to be put to bed in the early stages of integration strategy planning is hand-coding vs tool-based integration. In other words, what method are you going to use to physically carry out your integration project, a purpose-built, manually coded integration, or a third-party platform that is automated to perform specific tasks?

Let’s consider why a business may choose to hand-code their integrations…
It may seem like hand-coded integration projects are the easiest way to move forward - keeping things in-house, using your current IT and development teams and cutting out the middleman will keep costs down, right?
Of course, the pros to hand-coding seem compelling at first, with the ability to start immediately without onboarding new technology and training in new tools. However, if we shift our focus to a long-term integration infrastructure, the cons of hand-coding emerge and begin to change the balance for worse rather than better.
The reality of hand-coding data integration looks like this:
Businesses must evolve from thinking that data integration is a ‘one-off’ event - this thinking is rooted in the history of integration when traditional endpoints remained static. Today, endpoints are dynamic and constantly changing, meaning that your data integration tool needs to be flexible enough to keep up with the evolving data, technologies and business models of the modern-day.

Source: Cumulus
According to Gartner, using an integration platform over custom coding can reduce time to value for integration logic by up to 75%. For companies who do choose to deploy an integration platform within their strategy, the first step to finding the right tool is to evaluate three key areas:
1. Company Size
Small-to-medium businesses (SMB) have different requirements than enterprises.
Hubspot notes that SMBs have traditionally tended to favour cloud-based services for application integration or iPaaS. Whereas enterprises that traditionally have on-site application servers have opted toward enterprise integration or hybrid integrations.
2. Source Data and Target Systems
What data do you currently hold, and in what format? Is it mostly structured or a mixture of structured and unstructured data?
Think about which sources you hope to integrate. A project can range from more straightforward processes like integrating your transaction and purchasing data with your CRM data. Or it could be more complex, such as integrating your total multi-channel marketing stack to create a 360 degree unified view of your customers.
57% of marketers recognise integrating disparate technologies as the most significant barrier to success
Source: Hubspot
What you are hoping to gain from your integration project can only be achieved if you devise a strategy that can accomplish it.
Integration projects can perform many tasks: ETL, application integrations, cloud, real-time, virtualisation, cleansing, profiling, etc. Some tasks should come as standard, and some are more specialised - knowing what you need and what you don’t will help to keep your costs down.
Once you have these essential areas covered, you can start getting down to the nitty-gritty of your data integration strategy. We’ve outlined some best practice considerations that every successful data integration project, no matter what size or type, needs to look at:
As with any new marketing tactic or campaign, you should be setting out everything you hope to achieve with your data integration strategy ahead of time. Taking a broad range of eventualities into account can help you steer things in the right direction or get things back on track if something goes wrong.
What are your goals for your data integration project? They could be anything from using your unified data to gain insights that will improve your customer experience to increasing your marketing team’s efficiency by saving them time navigating multiple disparate data sources to create manual reports.
You should also think about your long-term company goals - understanding what types of data integration will bring value to your business will enable you to prioritise goals that meet broader business needs over departmental preferences.
Record your project goals using the SMART acronym to ensure they are Specific, Measurable, Attainable, Realistic and Time-bound.
Data integration projects, if done correctly, can take time to get up and running; this is because of the sheer volume of data that needs to be identified, accessed, cleansed, etc. There is also a period that needs to be allocated for research and onboarding of integration tools. Outlining a precise timescale for all of these activities will ensure you stay on track without skipping any vital planning steps or, conversely, taking too long to complete your integration project.
Another critical area of the timescale for your integration project is understanding how long it currently takes to process your disparate data into reports and dashboards manually. Knowing this information will help you to see what value your integration project has provided in terms of time-resource saving when the processes can be automated by an integration tool.
You plan on growing your business, don’t you? You want to expand, do more, achieve more and need an integration strategy to accomplish this.
Scalability is the measure of a systems’ ability to increase or decrease performance and costs in response to changing processing demands. Finding an integration platform that is flexible enough to suit your business is vital for growth and sustainability.
Lastly, you should outline a reasonable budget for your data integration project. Ensure that your budget is informed by research and is generous enough to onboard a product that meets the speed and capabilities of your business demands.
The cost of your data integration project should represent the amount that you’re willing to invest to streamline your business processes, gain greater insights from your data, better serve your customers and improve the efficiency of your team.
Integration is now the world's largest IT challenge with 1 of 6 IT dollars globally spent on integration
Source: Mulesoft research
When taking on data integration, it’s important to ensure that your team is ready, knows the integration process and benefits, and is aware of what training they will need to undertake. Preparing the people around you for change will ensure uptake and adoption of any third-party integration tool that you take on.
If you choose to manually code your integration, ensure that your team is capable of achieving the goals you set them. If you do not have the right skills on board, your integration project will ultimately fail, and be a waste of time and resources.
Alternatively, you could choose to onboard a third-party tool. Your IT and development team can be a vital asset during the onboarding process to ensure that any technical setup aspects are correctly handled.
Introducing data integration to your organisation can super-charge your data capabilities and bring great value to your marketing team. However, not all marketers are fully-formed data scientists. Investing in training your executives to understand and interpret their unified data and act upon the insights it produces, is just as important as what tool you decide to use to integrate your data.
Data integration increases data accessibility, but this benefit shouldn’t mean that everyone can access data that they do not need to carry out their job.
Integration projects introduce new processes, but you want to prepare your organisation for these changes without just logging people out.
This brings us to our next section...
Any business that is considering data integration must first think about their data management process - a series of different techniques and methods used to ingest, store and organise the data that is created by an organisation.
When planning your data integration strategy, ensure you think about the full data lifecycle and all of the stages that this includes as integration is just one part of your overall data strategy.
The full data lifecycle includes:

Data governance is defined by the Data Management Association (DAMA) International as “planning, oversight, and control over management of data and the use of data and data-related sources”. Governance should occur at every stage of the data lifecycle.
It’s a discipline that supports the overarching strategy of data management and it goes hand-in-hand with the success of your data integration strategy.
Data management can be visualised as a pin-wheel that sees data governance at the centre:
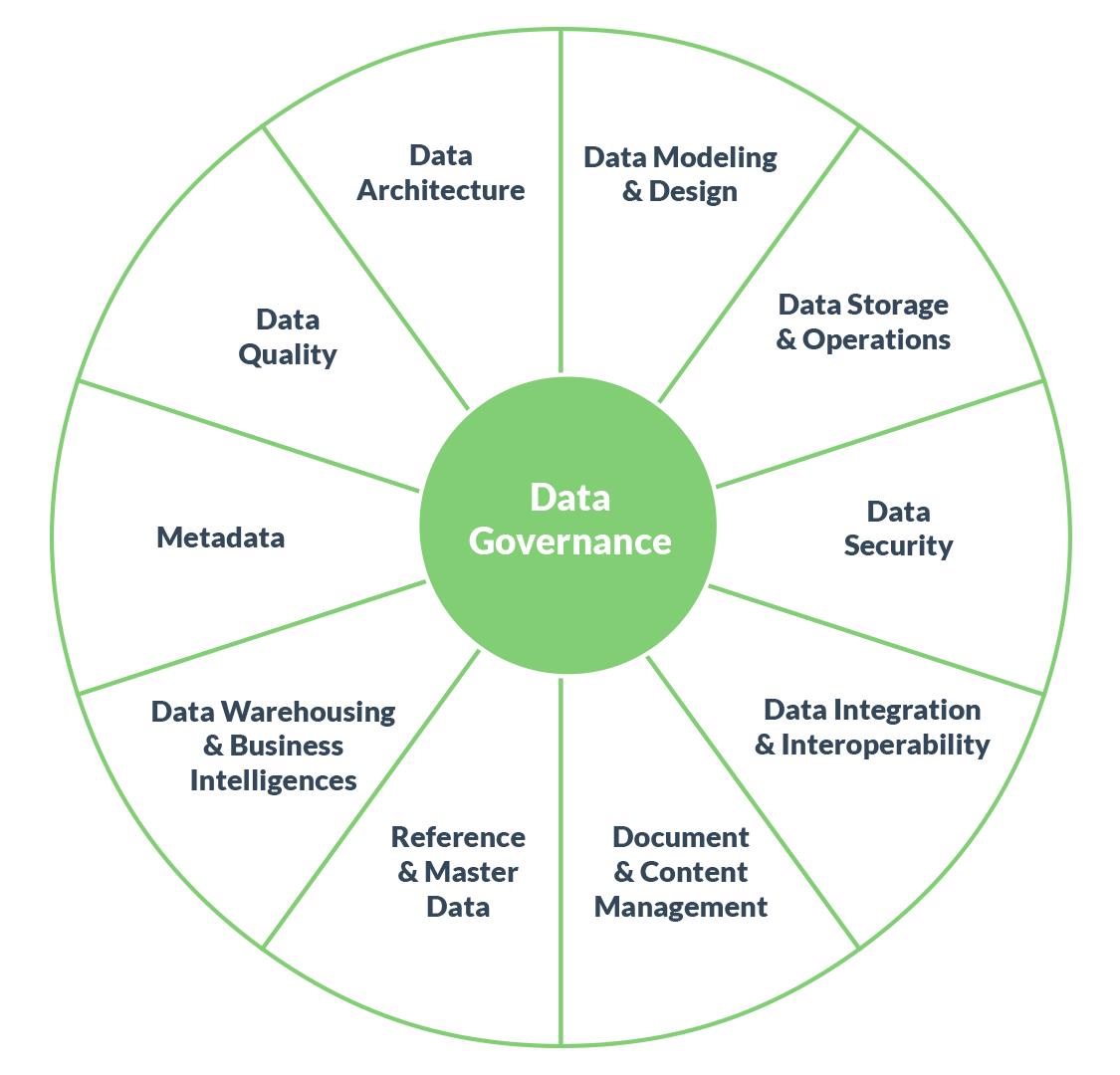
Source: Data Crossroads
Developing a data governance policy that touches each of these areas of data management outlines the methods, technologies and behaviours needed to properly manage data.
In the absence of a proper data governance policy, your company could be impacted by huge revenue losses. For example, Gartner has reported that the average financial impact of poor data quality, a subset of data governance, is a loss of $15 million per year.
Data governance is particularly important to data integration projects as it:

If you've made it this far, it's safe to say that you have a much better understanding of the concept of data integration, its importance and the benefits that it can bring to an organisation.
Let's quickly sum up what you stand to gain if you chose to invest:
Now, all that's left to do is put the wheels in motion and unify your data.
Hurree specialises in application integration for your marketing tech stack, ensuring that the tools you know and love can work better, together. We offer:
Why not book a quick chat with one of our friendly data integration experts so you can discuss how Hurree can help you today.

![]()
![]()